The Maturity Sequence
From my point of view the meta-philosophy of agile is iterative development and relies on
How Coroutines work in javascript, with a working simplified demonstration of how to set up a nested system for executing coroutines sequentially for data processing pipelines.
"Subroutines are special cases of ... coroutines." -- Donald Knuth.
tldr; version with the example is below
Recently I was adding a minimalist "recipe system" to an existing code base with the intention of refactoring it into a full system over time. A "recipe system" is a data reduction system driven by a "recipe", which is a series of steps. It's a concept, as far as I know, first envisaged at UKIRT in Perl by Paul Hirst et al. It was further developed at Gemini Observatory, adapted to a pyramid of python coroutines which filled the role of the recipe steps. I'll go into that pattern more in some other blog.
In this case I just needed to execute a list of coroutines, in JavaScript. Think of the steps on the list as executing business logic or data reduction, as coroutines they are functions that can yield values, like returning a value, but also be re-entered where they left off.
These steps are atomic units of interest to the problem domain. They can be written single mindedly since they are mostly decoupled from their control system. The control system in contrast is pure software artifact, problem domain neutral, while all problem domain behaviors are within the steps. To execute the list I needed to write a parent coroutine.
This routine provides the foundation of a control loop, since coroutines are presented to the callers as functions returning iterators. The iterator will iterate once each time coroutine it's calling calls yield. A coroutine can thus be written like an ordinary function but still cooperate with a control loop.
The calling function will always be a custom control loop. The body of the loop has control over continued execution. It can trap all errors. It can inspect output data and augment input data. It is able to perform services in order to offload them from the routines themselves, such as database modifications, to further purify the steps as atomic units concerned only with a specific step of relevance purely from the problem domain. It will obtain the recipe's initial input and dispatch the output as appropriate.
I was adding this directly into the existing code base because I've used generators and coroutines for a long time in python. I have also used them in javascript. I had a good idea of how I wanted it to work. However, the added issue of async functions and passing around promises got me confused and went in circles for a bit. I suffered cyclic off by one paralysis.
I did what I always prefer to do in such a situation; I stepped back and made a small stand-alone demonstration for myself, outside the real world code base I was working on. The demonstration is minimal, as they should be, with just the parts needed to demonstrate the structure of the design. It's a small software tool, meant to help the developer visualize concepts in isolation, so they can be better visualized when deployed in concert together.
In this case that is just the required two level nesting of coroutines. It's often true that code written for the demonstration is subsequently helpful in pieces, if not in the whole. The clarity of isolation a demonstration project provides can also prived the base interfaces which will be clear in practice. Also, such demonstrations can evolve over time as the design concept is enhanced and forks in the road are taken. In the long run they become the ideal implementation of the design originally demonstrated, and demonstrate if that is or is not actually a good thing.
These type of projects demonstrate useful patterns to team members and are to be encouraged. Time should be put aside for them. In this case I put my own time aside, rather than my clients.
I've found the simplest way to understand async and await is that:
return retVal; statements in a function marked async will really be a function wrapped in a Promise, which when resolved will become retVal. A promise is an object promising to eventually emit a return value.await someAsyncFooFunction(arg) will essentially pause at the given point in the function until the promise resolves. It also means you can not await an async function and pass the return value around as a promise, resolving it whenever you like.The whole scheme is to allow us to write functions that look like functions, and let the caller control when functions block or when they can run in parallel. Since the entire concept is single-threaded, mutual exclusion is not needed, but real parallelism happens due to I/O blocking. The low level functions don't have to cooperate with the schemes of their control systems.
Notably this means try/catch blocks can be used, an essential thing. I would say that the use of await and async obviates the desireability of most Promise handling. However, there are certain cases where it's very convienient, for example to start execution of a number of functions and awaiting Promise.all(..) of them to avoid sequentializing I/O.
As I said, in addition to coroutines, the system also uses the async/await syntax. It's worth noting that async functions are implemented under the hood as generators, and are a great example of what generators can do, and how linguistic sugar and like the async/await keywords can expose how expressive the concept is. At the time the coroutine itself was required to be synchronous by node. This was slightly unfortunate. (Now in 2021 async generators are supported in node and all browsers).
Given that, the stack will be like this:
I wanted the ability call an async function (the run action) which would loop over a coroutine (the steps action) that itself iterates over a sequence of functions (the primitive functions). The coroutine is used to weave the infrastructure into the execution of the pipeline while also isolating the primitives from the details of the execution context. The primitives just look like basic functions, input and return value with statements in between. The yield statement just allows returning values to the caller early, and seems to continue right away after from the point of view of this primitive function performing the "step".
This allows the primitives to be lightly constrained functions. They only worry about the data transformation they perform. This is good isolation of concern in general but is also especially useful in data pipelines since scientists and data science programmers, who will be programming the primitives and authoring recipes in principle, don't have to know the underlying execution system. They save time not knowing it, and that also enables evolving the control system and having more than one control system for different execution environments.
A data scientist writing an advanced data processing step might very likely not be skilled in the very different kind of infrastructural programming that is heavy with software artifacts from a whole different domain of abstractions. Their expertise is the discrete mathematics and physics involved in the step itself. In the business domain it's similar, the person that can implement a specified step in a business process is not particularly likely to find the abstraction of the control system easy to comprehend, even if it's kept minimal and with few lines of code. In fact, the few lines of code can make it very fragile, which a business step can often be conceived of an written by even a junior programmers, since it will have been specified in advance, and just be a simple function (albeit with yields).
Even when the same people write both the primitives and the control system, it's better to separate expertise with the control system from expertise in data transformation logic. They're simply two different domains that do not want to be married, but rather business partners.
I wrote two versions, one in which the primitives were regular functions, and another in which they are async functions. I had the impression maybe the promises were impacting my confusion so I excluded them on the first pass of my demonstration. Turns out that wasn't my problem. As it turns out, the only change required was that the control loop awaits the primitive function. As far as what the problem was, it was just getting the ideas straight.
In this blog I'll just go through the version with async primitives. The source code for the demonstration is at the bottom.
The coroutine needs to pass an input document to a primitive which will return a Promise. The Promise, when resolved, will provide the output document. In the demonstration I just pass the output received from one step into the next step as input (by passing it as the argument to next(..)), but in real systems the control loop will also perform other actions. These can include a wide variety of services, such as validating the document, saving it, normalizing it, annotating it with workflow information, providing debug output to logging systems, interpreting the document as an instruction, performing some service before the next step of the recipe, and a very wide and unrestricted array of possible and appropriate services.
This makes a recipe system built this way very good at integrating external systems into the data reduction process.
A generator is a type of function that yields return values instead of just returning them. The difference is that a return statement exits the function whereas a yield statement merely pauses a function. Execution can re-enter the function from the paused point, the function keeps running from there. What?!
The function scope is saved, preserving all local variables, and the controller (whoever called the function) takes over after the yield, until re-entering the routine. Obviously there has to be some syntax for re-entering just as there is a syntax for yielding, and it's possible to imagine a few.
Instead of calling the generator once, like a regular function ("subroutine"), you have to somehow call it multiple times, once for every time it yields. The caller also has to know when the coroutine is done yielding in order to stop reentering it. Fortunately, languages have long had an idiom for this, iteration, and convenient syntax for iterating, such as the for loop.
Classically one could easily iterate over an array, but using an iterator objects abstracts this. Any series of values can be yielded, linked lists, tree traversals, or a sequence of function calls. Indeed, the latter is the most general case, and generators are functions that, using in-language syntax, are packaged as an iterator compatible with all other types of iterators from the point of view of the runtime engine.
To the caller a generator looks like a function returning an iterator object. Iterator objects can always be repeatedly called until done using a for loop (for .. in in python and for .. of in javascript). The function return value behaves just as an iterable does, such as a built in iterator such as an array or list iterator, as well as custom iterator object such as database query iterator.
Therefore you simply iterate over the generator in a loop. The generator call goes where an array variable (etc.) would go (e.g. for i of arrayVar becomes for i of arrayGen()). This is the first really compelling thing about generators, at least it's why I started using them. You can replace a giant array variable with a small and efficient generator that "generates" the values that would be in the array. For example, at one time the common idiom in python (for i in range(1000)) would create an array of integers from 1 to 1000, the return value of the range(..) function. That's a lot of memory for no a good reason. It's tolerable for small ranges but becomes totally unworkable for millions. It's annoying at all sizes, although the syntax would otherwise be eloquent, what they call pythonic in the python world. The use of generators allowed this desirable syntax without that cost. The generator replacement (originally grange(..), but eventually this replaced the range(..) function itself) can create the values one at a time as they are needed. A range of 1000000 is not less efficient than a range of 10.
Another particularly useful application is the use of generators in database queries where there may be a large number of rows or documents returned. A generator allows you to hide all paging and cachine logic in the iterator itself, while the calling loop is able to concieve of the query as returned one at a time. This makes the code that's processing documents (or 'rows') blissfully ignorant about where the "rows" are coming from, or even if any batching and caching is going on. Coroutines are really amazing for isolating special purpose code, business routines, from control systems which are general purpose.
Outside the generator (to the caller) it looks like any other continuous iteration. Each iteration of the loop runs the generator function from the last yield to the next one.
for (yieldedVal of generatorFunction(arguments)) {
// do something or break to abandon generator
}
In the case of a coroutine, in addition to yielding values outward, upward in the stack, to the control loop, it has a way to receive values. In both javascript and python this is accomplished by the yield statement itself acting as an rvalue which returns a value, an lvalue, specifically the variable being set within the coroutine.
Unlike with a generator there isn't a built in language syntax for this, and we hav to use the iterator as an object and call it's next function, a part of the given languages iterator interface. Thus:
next(injectedValue) is called by the loop which is driving the coroutine with a control loop.injectedVal = yield outputDoc statement inside the coroutine receives the value. The coroutine variable, injectedVal, ends up being set to the control loop's argument to next(..), injectedValue. The variable outputDoc is what the previous call to next(..) returned. This is a source of confusion. The routine executes yield someVal and pauses. When re-entered it resumed first by accepting the injected value, the "return value" of the yield, and applying it as appropriate, e.g. setting a variable.
As mentioned above, the "for loop" syntax has no way to send in these new values. Instead, use of the coroutine has to be done in two steps, instantiating vs iterating. We are doing manually what the "for loop" does under the hood, calling the iterator's next method explicitly.
.next(..) member, usually in a loop. The end of the function is communicated the way any iterator is, with some sort of end of iteration return value or exception.Each call to .next(nextVal) returns whatever value the coroutine yields. The yield inside the coroutine "accepts" whatever the argument is to the subsequent .next(..) call. This little exchange is one of the things that originally make coroutines confusing from my point of view. Even after I inevitably think I've got them understood, I can find myself getting off by one. The yield statement pauses the code, and the return value is really whatever the control loops sends as an argument to (next). It should be thought of as a message.
To put this simply for purposes of this blog, which is to say grossly simplified:
lVariable = rStatementIn the coroutine you have:
const injectedVal = yield yieldedValue;
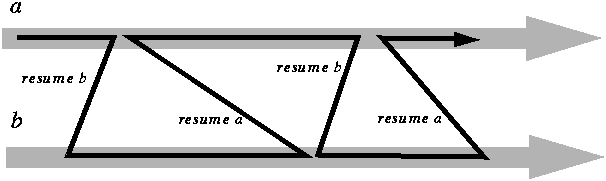
The injectedVal can be anything the controlling loop sends in as an argument to next(...). Strictly speaking it bears no particular relationship to the yieldedValue. This is a weird thing to me. What I'm used to with a statement in any language is that the lvalue bears a direct relationship to the variables, constants and arguments in the rvalue. It would be odd if parseDate(dateStr) returned a value of no relation to the dateStr passed in. But yieldedValue is just a value the coroutine is sending to its caller. And injectedVal is just a value the caller is sending to the coroutine. Coroutines cooperate in cooperative multitasking, which is why they are "co"-routines. It's specifically a cooperative multitasking model.
Normally y = x+2 means that y now has a relationship to x. It's a transformation of x by 2. Deep in the mind, I think I usually consider the "return value" as made from the "argument", and I suppose most programmers do as well. I mention it now because this was one of the things that has confused me in this case while adding async to the equation.
When this is the case, the function is a "pure function", but even impure function generally emit a return value related somehow to the arguments sent in.
With coroutines it's absolutely a message exchange going on, between the controlling function and the coroutine. The coroutine is cooperating with cooperative multitasking by saying only when is a good time for it to yield, at a minimum. Beyond that it is sending and accepting "messages" with yield statements. It passes the control flow back to the caller, and the caller passed control flow back to it.
The yeildedValue was sent to the calling routine. The calling routine sent the coroutine the injectedVal when it wanted it to run again, thus controlling it. Design-wise, the yield statement is a handoff point between two separate routines that are cooperatively multitasking, thus "co"-routines. The control routine can stop early but the coroutine is authority over when it's done.
To instantiate the coroutine object:
const cor = coroutine(inDoc);
At this point the body of coroutine has not run at all. Slightly confusing is the fact that the arguments to the coroutine have, however, been added to the coroutine's scope (so arguments that are function calls, for instance, will have been called). That's all that's happened. It's as if calling the function has executed only the creation of the stack and the opening brace, pausing before the first statement, with the function arguments declared but not yet used. The coroutine will only start to actually execute when next(..) is called for the first time.
next(), extra yield?Most instructions on making a coroutine in both python and javascript suggest that you call next() immediately after instantiating the coroutine. This acts as a sort of initiation that "starts up" the coroutine. This use of next is outside the actual use of the coroutine as an iterator. This means an extra yield in the coroutine, acting as something like an initialization ack (acknowledgement). To me, since a generator 'generates' a 'virtual' array in my mind, it also feels like having a phantom member at element -1 in the abstract array the coroutine generates. I don't prefer it.
It's worth understanding the issue, for example Harold Cooper's blog post on coroutines is still quite interesting and useful although it suggests using a wrapper function that does the above. This wrapper both instantiates the coroutine and makes an initial next call with no arguments. Absolutely no offense is intended to Harold Cooper, as I say, the suggestion is standard and his blog is nicely informative, so I once again suggest reading it. I reference it as proof that I didn't not make the issue up just to solve it :)
Here's Harold's coroutine wrapper. Notice of course it's a function that is called 'coroutine' which "starts" the argument "f". The function "f" is the actual coroutine.
function coroutine(f) {
var o = f(); // instantiate the coroutine
o.next(); // execute until the first yield
return function(x) {
o.next(x);
}
}
Rather than this I want to call the coroutine with every next() being called exactly the same way inside the iterative part of the execution loop, as done with the generator. I don't want to use the iteration function "next" in a special way. To do so imposes a constraint on the generator that it "begins" with an initial yield statement, and anything before the yield statement has special status as to what must or must not go there.
I want the coroutine entirely compatible with a generator, because the only difference is a generator needs only initial argument, not a series of them. If a control loop doesn't care about the values being emitted, it can use it just like a generator since a generator is just a coroutine that's not accepting other non-initial arguments.
I also want to call the primitive only with data it needs to do it's job, not a communication ack.
In my version each next(..) call will always send in the current document and each yield statement will return the document in its possibly intermediary states. In general one will also have a way to pass out requests for the control system to perform a service before the primitive is resumed. This is how you offload tasks to the control loops making them loosely coupled, so the control system control what databases or other services are used, and how, while business logic in routines specifies only that this data ought to be saved, or emailed, etc, at a high level. For the demonstration it is a "document" which is passed in and out, giving the control loop and the caller the chance to manipulate the document. An example use could be the control loop performing validations, logging, or sending messages to clients regarding the status of processing.
Most explanations of coroutines in Python are similar to the above. I think the apparent need for the extra next() call is like the natural occurrence of the one-off error, coming from the structure of the tool mixed with our prior habits. It's why there is no year 0 AD but there is year zero in ISO 8601:2004. There's always various solutions available.
The cost of this co-operation is that while it simplifies writing the routines, the control system needs to handle the baton handoff of messages clearly and as expected. Changes to the control loop can cause changes in behavior, obviously. For a likely example, if you have a loop inside the coroutine, you end up with a very different idiom if your yield is at the end of the loop rather than the beginning, because you, the coroutine, might be expecting the control system to do something for you, and it changes when that is.
It can always be sorted out, but t can be confusing. At the start, before the body, it's one removed from if it's at the bottom of the body. What it means to "finish" changes by one. This subtly changes the relationship between the calling code and the coroutine. Thus the structure of the control loop should be known and fixed for any coroutines written to be executed by it. Done correctly it will be clear when the control loops performs services, validation or logging.
The idiom demonstrated here allows the caller to be a control loop with no initiation of the loop prior to the iteration. The coroutine function in my demonstration is not a wrapper but the actual coroutine:
function *coroutine(inputDoc)
{
let doc = inputDoc;
for (let i = 0; i < 6; i++)
{
doc = yield primitive(doc);
}
}
Note: the '*' before the function name is how you declare a generator/coroutine in JavaScript.
Simulation: Above I'm simulating the "sequence" of functions from a list that I mentioned as the recipe with a loop repeatedly calling the same function. This is a simplification that doesn't affect the demonstration b/c it's grammatically equivalent to the loop over a list. Leaving it out saves me some standard plumbing the deployed system will need since there is no need for more than one routine. The target app where I started this will have a list in this pace, and also a wrapping object to help the control system handle the routine. Using this idiom, all the caller ever communicates to the coroutine is input documents and all it receives back is output documents.
In this pattern iteration immediately follows after construction with no handeshake, no "extra" next() call is used to get the coroutine "started".
If you give it some thought, you will see in this simple example, already, the type of flexibility the control loop achieves in this arrangement. The primitive transformations in the leaf coroutine do not care if they are called using a for loop. They don't care if the control loop dynamically modifies context. They don't care if any other primitive will or has been called. They don't care if they finish, even though it's up to them to decide when to finish in principle. The primitives don't even care if they are being called on the same machine as other primitives. In principle, they might even be resumed on an entirely different machine, though that's rarely economical so far. In practice, a primitive lives within a single thread, for the lifetime of the recipe, sharing memory with the rest of the thread.
On the control side, the infrastructure don't care what primitives do with data. They don't care if it's business information being "processed" or scientific data being "reduced" or anything else about domain logic. All it cares about is that the data going in and out is recognizable enough to identify, handle, and store it by itself. In this demonstration, that they're javascript objects. In the target application that they are readilly JSON-serializable javascript objects. If there are services, the control loop cares about the request-for-service messages, and shares knowledge of its schema with the coroutines.
The control system sees the primitive as "just an iterator", but the primitive itself sees itself not as an iterator at all, but as a "data transformation". I love this idea because I think it's the perfect isolation between domain logic (businessness logic, scientific logic, etc.) and control infrastructure.
The control loop doesn't have to care what's done to the data, but it can care. Routines don't have to be in a list, they can be in a tree, selected by datatype of command structures. It is available as a location for hooks that can, for example, validate data on it's way through the system, trigger messages to emit on a message bus, and provide system command and control features. A lot of actions can be performed on the control side that help make the system robust against badly behaved primitives, where at the least they are quickly isolated as the source of a failure in the data pipeline.
For me, calling the coroutine from the top control loop is also cleaner and easier to understand without an initializing next() call. Here is the control loop:
const inDoc = { type: "testdoc" };
const cor = coroutine(inDoc); // Instantiate coroutine
let done = false;
let doc = inDoc;
while (!done)
{
console.log(" input doc", doc);
const iterVal = cor.next(doc); // call next(..)
done = iterVal.done;
if (!done)
{
doc = await iterVal.value; // resolve Promise
console.log("output doc", done, doc);
}
else
{
console.log("done");
}
}
The coroutine is called with the input data to process, which is its purpose semantically, so that's good. The next(..) function in javascript returns an object with done and value keys. The done member becomes true when iteration is over and the value property is the value yielded by the coroutine. In this case that value is a promise to deliver the output document. The control loop awaits this document before proceeding because its output is needed as input for the next step.
Note that if the control loop has a way to know what routines can be run in parallel, it could start multiple routines and await using Promise.all(..).
A big part of why these two tightly interleaved systems won't interfere with each other is that the inter-operation is cooperative multitasking, they share a thread. Though the primitive is "controlled" by the control loop, the primitive also 'controls' the control loop insofar as it decides when it's willing to pause and let the control flow pass back to the control loop. The control loop has the greater control only because it does not have to resume the primitive, but the primitive has no choice but to release control back to the control loop, eventually, even if there is an error.
Here's the whole demonstration script:
"use strict";
async function primitive(doc)
{
if (typeof (doc.increment) === "number")
{
doc.increment++;
}
else
{
doc.increment = 1; // undefined means 0 so 0+1
}
return doc;
}
function *coroutine(inputDoc)
{
let doc = inputDoc;
for (let i = 0; i < 6; i++)
{
doc = yield primitive(doc);
}
}
(async() =>
{
const inDoc = { type: "testdoc" };
const cor = coroutine(inDoc);
let done = false;
let doc = inDoc;
while (!done)
{
console.log(" input doc", doc);
const iterVal = cor.next(doc);
done = iterVal.done;
if (!done)
{
doc = await iterVal.value;
console.log("output doc", done, doc);
}
else
{
console.log("done");
}
}
})();
Yes, that's where I like the braces. In fact, eslint polices that."brace-style": ["warn", "allman", {"allowSingleLine": true}].
I find that it's easier to match braces visually that way.
Source code likes being anthropomorphized.
Craig Allen © 2019, 2020
PS: If you think about it, the "extra" next is in fact required but the coroutine implementation itself already handles that initial yield, stopping right at the opening brace, the real start. No value is yielded, just like the examples above. I'm just leveraging this implicit yield.